An Intro to Compilers
How to Speak to Computers, Pre-Siri
tl;dr: Learning new meanings for front-end and back-end.
A compiler is just a program that translates other programs. Traditional compilers translate source code into executable machine code that your computer understands. (Some compilers translate source code into another programming language. These compilers are called source-to-source translators or transpilers.) LLVM is a widely used compiler project, consisting of many modular compiler tools.
Traditional compiler design comprises three parts:
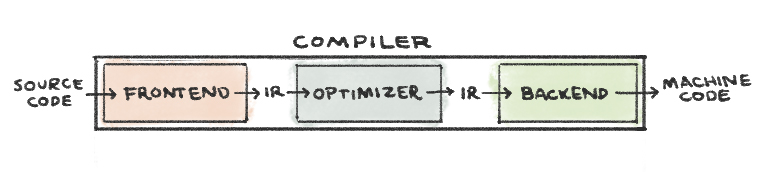
- The Frontend translates source code into an intermediate representation (IR)*.
clangis LLVM’s frontend for the C family of languages. - The Optimizer analyzes the IR and translates it into a more efficient form.
optis the LLVM optimizer tool. - The Backend generates machine code by mapping the IR to the target hardware instruction set.
llcis the LLVM backend tool.
* LLVM IR is a low-level language that is similar to assembly. However, it abstracts away hardware-specific information.
Hello, Compiler 👋
Below is a simple C program that prints “Hello, Compiler!” to stdout. The C syntax is human-readable, but my computer wouldn’t know what to do with it. I’m going to walk through the three compilation phases to make this program machine-executable.
(You can imagine the program waving to the compiler as it moves through the compilation process.)
// compile_me.c
// Wave to the compiler. The world can wait.
#include <stdio.h>
int main() {
printf("Hello, Compiler!\n");
return 0;
}The Frontend
As I mentioned above, clang is LLVM’s frontend for the C family of languages. Clang consists of a C preprocessor, lexer, parser, semantic analyzer, and IR generator.
-
The C Preprocessor modifies the source code before beginning the translation to IR. The preprocessor handles including external files, like
#include <stdio.h>above. It will replace that line with the entire contents of thestdio.hC standard library file, which will include the declaration of theprintffunction.See the output of the preprocessor step by running:
clang -E compile_me.c -o preprocessed.i-
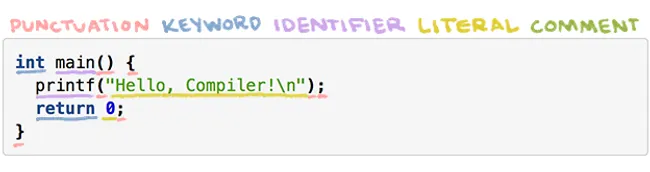
The Lexer (or scanner or tokenizer) converts a string of characters to a string of words. Each word, or token, is assigned to one of five syntactic categories: punctuation, keyword, identifier, literal, or comment.
Tokenization of compile_me.c
-
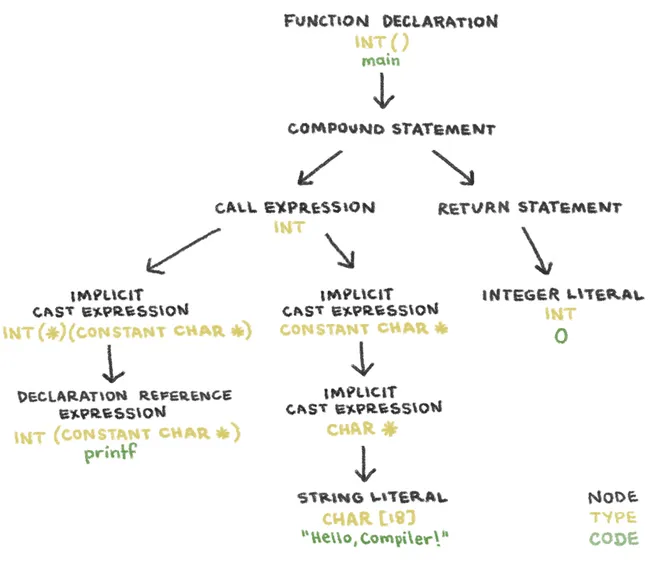
The Parser determines whether or not the stream of words consists of valid sentences in the source language. After analyzing the grammar of the token stream, it outputs an abstract syntax tree (AST). Nodes in a Clang AST represent declarations, statements, and types.
The AST of compile_me.c
-
The Semantic Analyzer traverses the AST, determining if code sentences have valid meaning. This phase checks for type errors. If the main function in compile_me.c returned
"zero"instead of0, the semantic analyzer would throw an error because"zero"is not of typeint. -
The IR Generator translates the AST to IR.
Run the clang frontend on compile_me.c to generate LLVM IR:
clang -S -emit-llvm -o llvm_ir.ll compile_me.cThe main function in llvm_ir.ll
; llvm_ir.ll
@.str = private unnamed_addr constant [18 x i8] c"Hello, Compiler!\0A\00", align 1
define i32 @main() {
%1 = alloca i32, align 4 ; <- memory allocated on the stack
store i32 0, i32* %1, align 4
%2 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([18 x i8], [18 x i8]* @.str, i32 0, i32 0))
ret i32 0
}
declare i32 @printf(i8\*, ...)The Optimizer
The job of the optimizer is to improve code efficiency based on its understanding of the program’s runtime behavior. The optimizer takes IR as input and produces improved IR as output. LLVM’s optimizer tool, opt, will optimize for processor speed with the flag -O2 (capital o, two) and for size with the flag -Os (capital o, s).
Take a look at the difference between the LLVM IR code our frontend generated above and the result of running:
opt -O2 -S llvm_ir.ll -o optimized.llThe main function in optimized.ll
; optimized.ll
@str = private unnamed_addr constant [17 x i8] c"Hello, Compiler!\00"
define i32 @main() {
%puts = tail call i32 @puts(i8* getelementptr inbounds ([17 x i8], [17 x i8]* @str, i64 0, i64 0))
ret i32 0
}
declare i32 @puts(i8\* nocapture readonly)In the optimized version, main doesn’t allocate memory on the stack, since it doesn’t use any memory. The optimized code also calls puts instead of printf because none of printf’s formatting functionality was used.
Of course, the optimizer does more than just know when to use puts in lieu of printf. The optimizer also unrolls loops and inlines the results of simple calculations. Consider the program below, which adds two integers and prints the result.
// add.c
#include <stdio.h>
int main() {
int a = 5, b = 10, c = a + b;
printf("%i + %i = %i\n", a, b, c);
}Here is the unoptimized LLVM IR:
@.str = private unnamed_addr constant [14 x i8] c"%i + %i = %i\0A\00", align 1
define i32 @main() {
%1 = alloca i32, align 4 ; <- allocate stack space for var a
%2 = alloca i32, align 4 ; <- allocate stack space for var b
%3 = alloca i32, align 4 ; <- allocate stack space for var c
store i32 5, i32* %1, align 4 ; <- store 5 at memory location %1
store i32 10, i32* %2, align 4 ; <- store 10 at memory location %2
%4 = load i32, i32* %1, align 4 ; <- load the value at memory address %1 into register %4
%5 = load i32, i32* %2, align 4 ; <- load the value at memory address %2 into register %5
%6 = add nsw i32 %4, %5 ; <- add the values in registers %4 and %5. put the result in register %6
store i32 %6, i32* %3, align 4 ; <- put the value of register %6 into memory address %3
%7 = load i32, i32* %1, align 4 ; <- load the value at memory address %1 into register %7
%8 = load i32, i32* %2, align 4 ; <- load the value at memory address %2 into register %8
%9 = load i32, i32* %3, align 4 ; <- load the value at memory address %3 into register %9
%10 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([14 x i8], [14 x i8]\* @.str, i32 0, i32 0), i32 %7, i32 %8, i32 %9)
ret i32 0
}
declare i32 @printf(i8*, ...)*Here is the optimized LLVM IR:*
@.str = private unnamed_addr constant [14 x i8] c"%i + %i = %i\0A\00", align 1
define i32 @main() {
%1 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([14 x i8], [14 x i8]\* @.str, i64 0, i64 0), i32 5, i32 10, i32 15)
ret i32 0
}
declare i32 @printf(i8\* nocapture readonly, ...)Our optimized main function is essentially lines 16 and 17 of the unoptimized version, with the variable values inlined. opt calculated the addition because all of the variables were constant. Pretty cool, huh?
The Backend
LLVM’s backend tool is llc. It generates machine code from LLVM IR input in three phases:
-
Instruction selection is the mapping of IR instructions to the instruction-set of the target machine. This step uses an infinite namespace of virtual registers.
-
Register allocation is the mapping of virtual registers to actual registers on your target architecture. My CPU has an x86 architecture, which is limited to 16 registers. However, the compiler will use as few registers as possible.
-
Instruction scheduling is the reordering of operations to reflect the target machine’s performance constraints.
Running this command will produce some machine code!
llc -o compiled-assembly.s optimized.ll
\_main:
pushq %rbp
movq %rsp, %rbp
leaq L_str(%rip), %rdi
callq \_puts
xorl %eax, %eax
popq %rbp
retq
L_str:
.asciz "Hello, Compiler!"
This program is x86 assembly language, which is the human readable syntax for the language my computer speaks. Someone finally understands me 🙌
Resources